1.3.1 处理器
计算机的“大脑”是CPU。CPU从内存中取出指令并执行它们。每个CPU的基本周期是从内存中取出第一条指令,解码确定其操作数和类型,执行,如此循环直至程序结束。程序以这种方式运行。
每个处理器都有一组它可以执行的特定指令。因此一个x86 CPU不能执行ARM架构的程序,反之亦然。因为访存以获得指令或数据比执行一个指令耗时更长,所有的CPU均包含一些寄存器以保存一些关键变量和临时结果。因此,指令集通常包含一个从内存中加载一个字到指定寄存器的指令,和一个将寄存器中一个字写入到内存的指令。其他的指令将寄存器、存储器或二者中的两个操作数处理得一个结果,例如求两个字的和,结果存入寄存器或主存。
除了用来保存变量和临时结果的通用寄存器,大多数计算机都有几个对程序员可见的特殊寄存器。其中一个是程序计数器(Program Counter,PC),储存了下一条指令的地址。当这条指令被取走后,PC更新指向到下一条指令。
另一个寄存器是栈指针(Stack Pointer,SP),指向了当前内存栈的顶部。栈包含了每个已进入但尚未退出函数的数据。函数的栈保存了输入参数,局部变量,以及不在寄存器中的临时变量。
还有一个寄存器是PSW(Program Status Word)。这个寄存器包含描述当前状态的bit,数据由当前指令,CPU优先级,模式(内核或用户),以及其他的控制bit决定。用户程序通常可以读取整个PSW但是可能只能写其中的几个bit。
PSW在系统调用以及I/O中起重要作用。操作系统必须清楚所有的寄存器。当CPU时间复用时,操作系统经常会停止一个运行的程序并且开始另一个。每次停止一个程序,操作系统必须保存所有的寄存器以便程序之后运行时恢复。
为提高性能,CPU设计者早已放弃了简单的一次取指,译码,执行一条指令的方式。许多现代CPU可以同时执行多个指令。例如,一个CPU可能有单独的取指,解码和执行单元,所以当它执行指令n时,它可以同时译码指令n+1,并且取第n+2条指令。这样的组织方式被称为流水线(pipeline)。图1-7(a)展示了一条三级流水线。通常情况下流水线都比较长。在大多数流水线设计中,如果一条指令被取指,那么它就必须被执行,即使它也许只是一条条件跳转指令。流水线使得编译器作者和操作系统作者非常头痛,因为它们暴露了底层的复杂性而且他们必须处理这种复杂性。
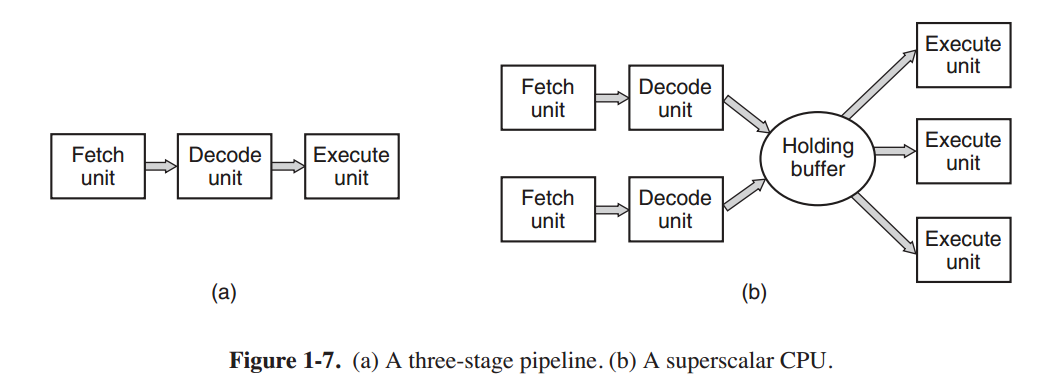
比流水线更先进的设计是超标量(superscalar)CPU,如图1-7(b)。在这个设计中有多个执行单元,如一个整数运算单元,一个浮点运算单元,一个布尔运算单元。CPU一次取两条或者更多的指令,解码,储存至缓存直至它们可以执行。只要有一个执行单元空闲,CPU就会遍历缓存查找是否有空闲的执行单元可以处理的指令。如果有就将这条指令交由其处理并移出缓存。这意味着这样的设计中指令经常是被乱序执行的。重要的是由硬件保证执行结果与顺序执行的结果相同,但是正如我们所见,额外的复杂度又强加给了操作系统。
正如之前所说,除了一些极简单的嵌入式CPU,大多数CPU均有两个状态,内核模式及用户模式。通常由PSW中的一位控制模式。当运行于内核模式时,CPU可以执行指令集中的任何指令并且使用任何硬件功能。桌面计算机和服务器中的操作系统一般运行在内核态,拥有访问硬件的全部权限。在嵌入式操作系统中,一部分运行在内核态,操作系统的剩余部分运行在用户态。
用户程序总是运行在用户态,只可以使用指令集的子集。同时也不能执行涉及I/O以及内存保护的指令。当然更不能通过设置PSW的相关bit进入内核态。
为获取操作系统的服务,用户程序必须产生一个系统调用。这将导致系统陷入内核并且调用操作系统。TRAP指令将从用户态切换到内核态并且转到操作系统。操作完成后控制权返回用户程序。我们会在本章后面详解系统调用机制。目前暂时认为这是一种从用户态到内核态的特殊调用过程。 (As a note on typography, we will use the lower-case Helvetica font to indicate system calls in running text, like this: read. 此处为原书的字体约定)
值得一提的是,计算机除了执行系统调用会产生自陷以外还有别的指令。大多数的其他自陷都是由于硬件对特殊情况的警告产生,如尝试除0或浮点数溢出。但是无论如何,只要发生了自陷,操作系统都会接管系统并且决定下一步要做什么。有时程序必须因为产生错误被终止,有时错误可以被忽略(比如浮点数被设为0)。最后,当程序声明它想自行处理某些特定的异常情况,控制权也会交还用户程序以任其自行处理。
多线程及多核心芯片
Moore定律表明芯片中的晶体管数目每18个月翻一番。这个“定律”并不是什么动量守恒一样的物理定律,而是Intel联合创始人之一的Gordon Moore的观测经验。Moore定律已经生效了超过30年,并且有望继续保持10年。在那之后每个晶体管包含的原子数目太少以至于量子效应开始显现,阻碍晶体管的进一步缩小。
越来越充裕的晶体管数目引发了一个问题:应该如何高效地组织它们?我们之前提到了一个方法:超标量体系架构,同时准备多个功能单元。但是新工艺可以容纳的晶体管数目继续增加,一个很容易想到的办法就是增大CPU的缓存。这确实发生了,可是增大缓存带来的收益也越来越少。
很明显,下一步就是不仅仅重复一些功能单元,而是重复一些控制逻辑。Intel的Pentium 4处理器增加了这些特性,称为多线程或超线程(hyperthreading,Intel对其的称呼)。其他的一些CPU也有类似功能,包括SPARC,Power 5,Intel Xeon,和Intel的Core家族。简要来说就是允许CPU同时保存两个不同线程的状态并且在其中做快速的纳秒级的切换(线程是一种轻量级进程,细节将会在第二章讨论)。如果一个进程需要读取内存数据(这需要很多CPU周期),一个多线程CPU可以切换到另外一个线程。但是多线程技术并不提供真正的并行处理。虽然只能同时运行一个线程,但是线程切换时间被减小到了纳秒级。
多线程也为操作系统增加了麻烦,因为每一个线程在操作系统看来就是一个独立的CPU。假设一个系统有两个CPU,每个CPU2个线程,那么操作系统将认为这是一个4CPU系统。如果系统当前仅两个进程,那么操作系统就有可能将所有的任务分配到同一个CPU上而另一个CPU完全空闲。这种情况下的效率反倒是远远赶不上一个CPU一个线程了。
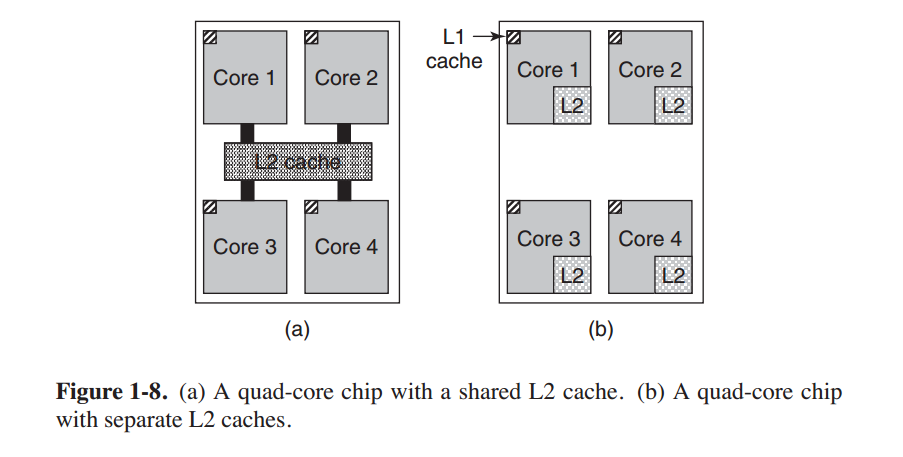
除了多线程,许多CPU芯片上都有4个,8个或者更多的完整核心。图1-8显示的多核心芯片包含了4个核心,每个都是独立的处理器(缓存会在下面解释)。有些处理器,如Intel Xeon Phi和Tilera TilePro单块芯片上已包含了超过60个核心。充分使用核心数目如此多的系统毫无疑问需要一个多核心操作系统。
顺便一提,说起绝对数量,没有什么芯片比得上现代GPU(Graphics Processing Unit)。一个现代GPU包含上千个小核心。这样的结构非常擅长处理大量并行的小规模计算,例如图像程序中的渲染。但是它们不擅长串行的任务,也难以编程,尽量GPU对操作系统来说很有用(例如加密或处理网络流量),但是操作系统本身运行在GPU上仍然不太可能。